Operating Model Deployment Kit
The operating layer for cooperative AI work, across people, teams, tools, and time.
AI gives individuals leverage. The kit makes that leverage compound. First for the operator. Then the team. Then the organization.
AI created a cooperation problem.
AI gives every individual leverage. What's missing is the layer that lets that leverage compound across people, teams, and time. Not because anyone is doing anything wrong; because context, decisions, quality standards, and learning stay trapped inside individual builders' sessions.
Builders are emerging in every function, each setting up their own AI context across whichever tool fits the moment, sometimes Claude Code, sometimes Hyperagent, sometimes Cursor, sometimes a raw LLM analyzing a document. Each session is its own loop of revision cycles to drag the output up to a usable bar. Decisions don't carry between teams. Quality is per-builder. The work compounds in some places and not others. AI makes individuals faster; the organization needs the work to carry across people, tools, teams, and time.
Most organizational dysfunction in technical systems comes from upstream decisions that were made informally, never written down, and then relitigated by every downstream actor in slightly different ways. The fix is mechanical: name the layers, write the decisions, inherit them, require new work to either inherit or supersede with rationale.
This problem isn't abstract. When my uncle asked me for help with his app, he'd already hired someone, watched scope creep, and was thousands of dollars in with nothing to show. I'm resource-constrained too. I couldn't sit with him to rebuild. But I could give him my process. The kit started as an experimental function of one I run on my own work. Scaling it into a complex system is what let me hand him something instead of sitting with him. It's also what lets my own thinking compound instead of evaporate between sessions.
The problem is not building with AI. The problem is building together with AI.
The kit turns isolated AI work into shared operating context.
The kit is a set of files any adopter can drop in. Answer a few setup questions to tailor it to your context. After that, you work as usual. When something significant changes (a new manager, a new AI model, a new regulation), the kit revisits itself and updates only what shifted. And you do not have to use all of it. Take what fits, leave what doesn't. Hand a single file to any LLM and ask "help me make sense of this." That works too.
The reference point is the kit-of-skills pattern Andrej Karpathy and others have shipped: a kit that helps you build and ship one product. Powerful for the project it's scoped to. The Operating Model Deployment Kit goes further. It's built for switching contexts quickly with shared learnings carrying across each domain, shipping multiple solutions in parallel from a point of shared understanding. Three structural pillars make cooperation possible. Three amplifying properties make the kit get bigger over time.
The kit is a shape, not a system.
Not an LLM. Not a runtime. A set of files and conventions that go INTO whatever context surface your tool uses: Claude memories, Cursor rules, Hyperagent skills, ChatGPT projects, plain markdown. The kit gives content a place in a clear hierarchy: top-level principles, mid-level decisions, per-instance tweaks. The same hierarchy lands inside every system you load it into. Wherever the content travels, every system reads it at the right level.
Same kit. Different deployments. Decisions inherited or superseded.
The kit names eight decision layers, from strategy at the top to integrations at the bottom, and treats each as a precondition for the next. Strategy doesn't just sit in a deck; it cascades through every team that adopts the kit. A team can override a parent decision only by writing the rationale into a decision record. The original stays on file. Patterns that work in one team surface upward as defaults; differences become explicit, not silent.
Outputs carry their evidence, provenance, and reproducibility pins.
Every AI output is logged with how it was made: the model version, the prompt, the tools called, the data snapshot. Anyone can reproduce, audit, or trust the output without paging the original author. Status reports name what is incomplete, why, and when it returns to ready. Concrete instead of approximate.
Agree on mature, drive toward it, auto-approve when evidence is there.
The kit names what "mature" looks like up front and iterates toward it, asking questions along the way. Less prescribing, more auto-approvals when evidence is there. When it isn't, refusal kicks in: the status check will not mark something complete without evidence, the release-readiness check will not pass without an evaluation baseline, the reproducibility check will not pass unless the model version, prompt, tools called, and data snapshot are all logged. Best practices reinforce as you go, instead of getting relitigated each session.
Same kit, different content per layer. For builders, operators, deciders, and creators. The layers grid in The structure below lets you switch perspective.
What makes the kit get bigger over timeEvery session leaves behind decisions, status, unknowns, and next moves.
Each agentic session adds to a shared knowledge base. Decisions get recorded so future readers know why. Tried-and-rejected paths get logged so others do not repeat them. Status reports are versioned over time. Six months in, the team's collective knowledge is bigger than what any single person could have built alone.
The hierarchy travels across tools.
Claude, Cursor, Hyperagent, ChatGPT, or any LLM can consume the same operating model. (Substrates like Airtable, GitHub, or plain markdown can hold it too.) The kit isn't an alternative to those tools' context systems (memories, rules, skills, projects). It's the shape of the content you put into them. Each piece names what level it sits at: a top-level principle, a recorded decision, a per-instance tweak. So when you drop the same content into Claude or Cursor or Hyperagent, every system reads it the same way and weights it at the right level. Hand a single file to any LLM and ask "analyze this and extract the strengths." Partial consumption is valid because every file carries its own structure.
The operating model updates when reality changes.
Drop the kit in. Setup questions tailor it to context. Operate; new context surfaces. The kit revisits itself when something material shifts: a manager change, an AI model bump, a regulation, a quarter that has elapsed. It updates only what needs updating. The kit does not freeze at launch; it refreshes when context changes.
Context should survive the session. Quality should not depend on who ran the prompt. Decisions should be inherited, not rediscovered.
AI compressed the cost of completeness.
Practices that were rationally skipped in 2020 (evaluation baselines, decision records, frontmatter on every artifact, reproducibility pinning, layered tests) cost a fraction now of what they used to cost when AI assistance was unavailable. The cost of omitting them has not compressed: a silent regression still takes weeks to debug, a relitigated decision still consumes meeting hours, a stale prompt still erodes trust. The economics flipped.
The argument is not "do this because it is correct." It is "do this because the math no longer says skipping is cheaper." Work that was not possible to get to "perfect" at any time in the last 10 years becomes structurally tractable.
The work around AI work is becoming the work.
The kit's objects are relational. Airtable makes them live.
The kit ships as a folder of files. It works on any repo you already use: GitHub, Notion, Confluence, plain disk. The reason Airtable belongs at the top of the list is that the kit's core objects are already relational by design. On a flat-file substrate you read, edit, and grep them. On Airtable, they become a living operating system: records hold state, interfaces fit each audience, automations fire on behavior triggers, and AI scaffolds, summarizes, validates, and detects drift in real time.
The relational objects already in the kit
Pods · Layers · Decisions · Owners · Maturity states · Scorecards · Findings · Triggers · Handoffs · Relationships
State that updates instead of decays.
Maturity scorecards become live records, not stale Markdown. A layer demoted from mature to partial updates the moment the drift is detected; the scorecard archive history is automatic.
Builders, leads, and stakeholders see different views of the same truth.
One base, many interfaces. The function lead sees a portfolio scorecard; the practitioner sees their pod's open backlog; leadership sees the cross-pod roll-up; auditors see the decision archive.
Refusal conditions become rules, not memory.
The kit's behavior triggers (when a layer marker shifts, when a relationship goes stale, when a rescaffold trigger fires) become Airtable automations that route findings to owners and create rescaffold tasks automatically.
Scaffold, summarize, validate, detect drift.
AI inside Airtable scaffolds new pods from the localization answers, summarizes session logs into hindsight notes, validates layer artifacts against the brief, and detects when reality has drifted from the recorded state.
The kit turns AI sessions into institutional memory. Airtable is where that memory finds its strongest operational home.
Before and after, line by line.
What concretely shifts when the kit lands. Each line is a real failure mode the kit replaces with a structural answer.
Before the kit
- Context is trapped in sessions
- Decisions live in Slack
- Quality varies by builder
- Docs go stale
- Handoffs rely on memory
- Integrations are assumed live
- AI work compounds unevenly
After the kit
- Context is shared
- Decisions are recorded and inheritable
- Quality gates are enforced
- Artifacts have lifecycle
- Handoffs are structured
- Relationships require evidence
- AI work compounds across teams
What that looks like for a single rule, "always cite sources":
The rule lives as a one-liner. The reader can't tell its weight.
"Always cite sources" sits as a one-liner in a Claude memory, a Cursor rule, or a project README. There's no signal of how heavily to weight it. It might be a passing note. It might be load-bearing. The reader can't tell. As more notes accumulate, it gets buried alongside per-instance tweaks of equal visual weight.
Same rule, but recorded with its weight.
The same rule sits in your Claude memory (or Cursor rule, or Hyperagent skill, or wherever your context lives), but now recorded as a top-level principle. The kind that applies to every piece of work, not a per-instance tweak. It carries why we made it and what we considered instead. The reader sees the rule AND its weight: load-bearing, not optional.
The same hierarchy is present wherever the content lives.
The same files dropped into Claude memory, Cursor rules, Hyperagent skills, or plain markdown all carry the same hierarchy. Top-level principles read as principles. Decisions read as decisions. Per-instance tweaks read as tweaks. Each piece names its own level, so any LLM you hand the content to digests and weights it at the appropriate level. The structure lives in the content, not in the tool.
The kit is not a concept deck. It ships as operational machinery.
Take what fits. Leave what doesn't.
You do not need to adopt the whole kit. Take a layer template. Borrow the decision-record format. Copy the maturity-scorecard structure. Or hand any single file to your AI tool of choice and ask it to extract what fits. Three of the most common ways in:
Compound your own work, session by session.
Hand any file to Claude, Cursor, or Hyperagent and ask it to extract what fits. Use the kit's decision-record format to remember why you chose what you chose. Maturity scorecards keep your own work legible to your future self. Solo operators get the same gates and the same compounding the team version gets.
Share context across the people you work with.
Decisions, setup, scaffolding stay legible to the next person without re-explanation. The substrate carries the knowledge so the team does not have to.
Talk about direction as use cases firm up.
A common starting point for the conversation about flexible, standardized resources and rules. Use the kit's vocabulary to compare notes across functions; adopt what proves useful.
Eight decision layers and five phase modes.
Each decision layer is a precondition for the next. Skipping creates the retrofit trap: a later decision forces redoing earlier work, often three times. Strategy decisions cascade down; cross-platform glue decisions cascade up. The kit operates by five phase modes (bootstrap, discovery, scaffold, operate, rescaffold). Most sessions are in operate-mode; rescaffold-mode fires when context shifts.
Switch lens
Each layer's SCOPE is universal. What it CONTAINS varies per function (per ADR-0006). Pick yours; every layer translates, including L0's upstream organizational inputs.
Click any lens to translate the layers below. Currently viewing: Create.
Learning is not a means to a deployment. Learning is the deployment. The kit lands with an initial scaffold (thorough, intense), then continuously rescaffolds as context grows. Subsequent scaffolds are lighter than the first and target only the surfaces where context shifted.
Load the brief, orient the operator, prepare for discovery.
Recursive questioning to understand the deployment context: function, sponsor, substrate, rhythms.
Render templates against gathered context. Populate layer artifacts. Ship initial decision records.
Run the deployed pod day-to-day. Drain inboxes. Write decisions as they arise. Log session activity.
Revisit affected scope when triggers fire. Update only what context shifted; leave the rest alone.

Bootstrap → Discovery → Scaffold → Operate ↔ Rescaffold.
Linear from bootstrap to scaffold; cyclical between operate and rescaffold thereafter. The kit lives mostly in operate-mode and dips into rescaffold when triggers fire.

Six families of trigger that warrant a rescaffold.
Validation findings of layer-level scope. Honest unknowns resolved. Structural shift in the function served. Sponsor change. Kit version bump. Calendar cadence (quarterly minimum). The system schedules its own revisits; frameworks do not rot silently.
The architecture, visualized.
Three diagrams to land the kit's shape: how a team's pod is organized internally; how pods nest and compose recursively (the kit itself is a pod); and how a pod connects out to the runtime, substrate, and regulatory environment around it.
Diagrams below carry the kit's locked visual vocabulary (warm, editorial). The microsite shell follows Airtable's Tech Docs design system. The kit's diagrams stay in their own family by design.

The eight decision layers, governance scaffolding, skills, and the relationships between them.
One pod, all the moving pieces. Strategy at the top (L0), integration glue at the bottom (L7). Decision records, session logs, and a backlog hang off the side. Skills and templates plug in where needed. Every team that adopts the kit lands as one of these.
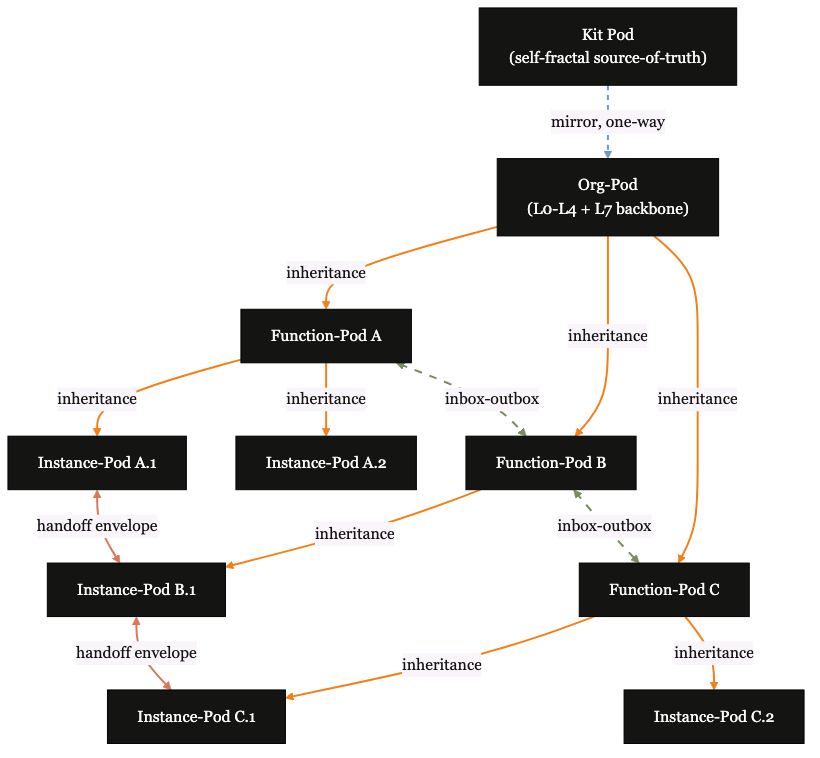
Kit → Org → Function → Instance. Each level is a pod operating by the same governance shape, recursively.
The kit itself is a pod. An org adopting the kit is a pod that mirrors from it. Each function is a sub-pod that inherits from the org. Instances within the function are sub-pods of the function. Same governance shape at every level. The kit is its own training material.
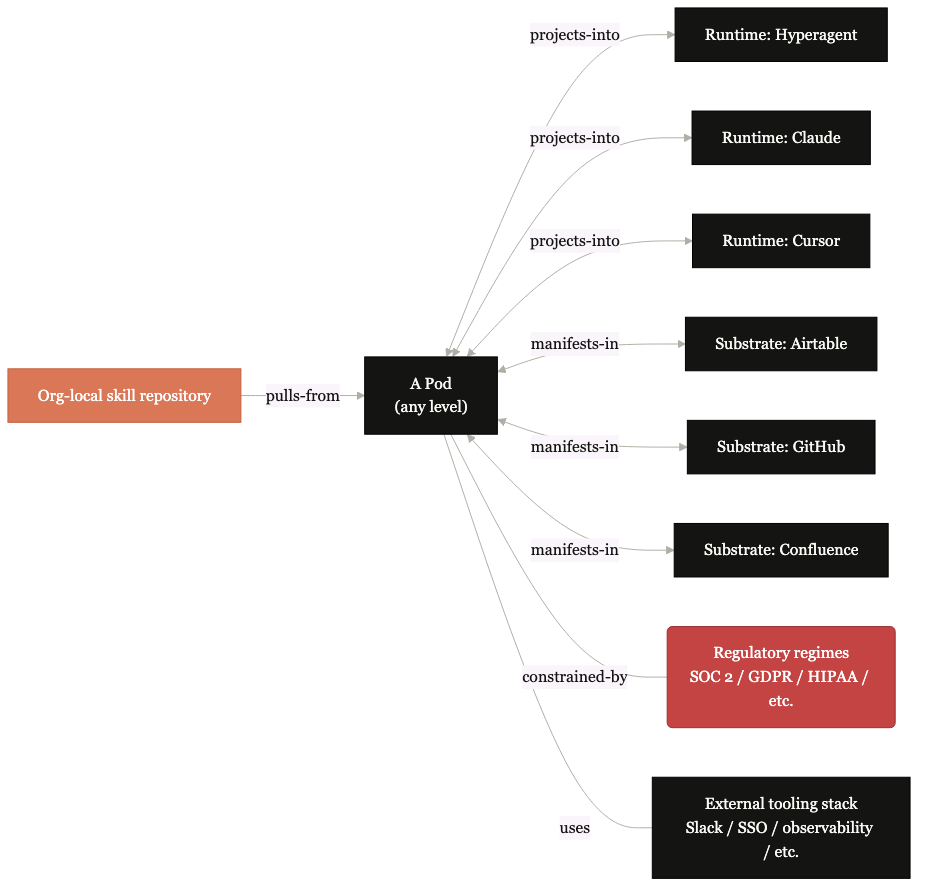
Runtimes, substrates, the org's own skill repository, and the regulatory environment surrounding the pod.
The pod doesn't operate in a vacuum. It runs on a tool (Claude Code, Hyperagent, Cursor, or another), stores its content on a substrate (Airtable, GitHub, Confluence, hybrid), pulls skills from the org's local repository if one exists, and operates within a regulatory environment. All four surfaces flex per deployment.
The mechanisms that make it work.
Three mechanisms do most of the heavy lifting. Refusal-conditioned skills enforce the standard structurally. The reproducibility four-pin makes every output auditable. Named failure modes give the kit a defensive vocabulary it inherits.
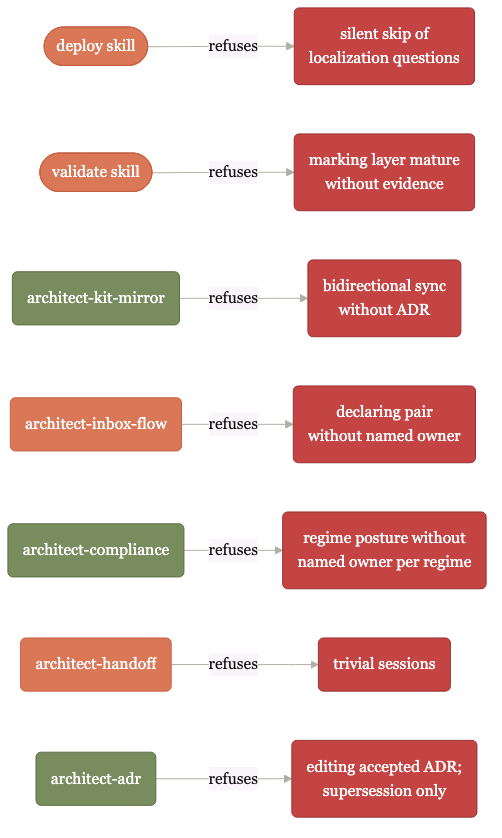
Each kit-native skill encodes refusal conditions.
The verification skill refuses to mark a layer mature without evidence. The release-readiness check refuses without an evaluation baseline. The reproducibility check refuses without all four output details. The mirror-discipline skill refuses bidirectional sync without a decision record. Standards usually rely on hope; this one refuses by structure.
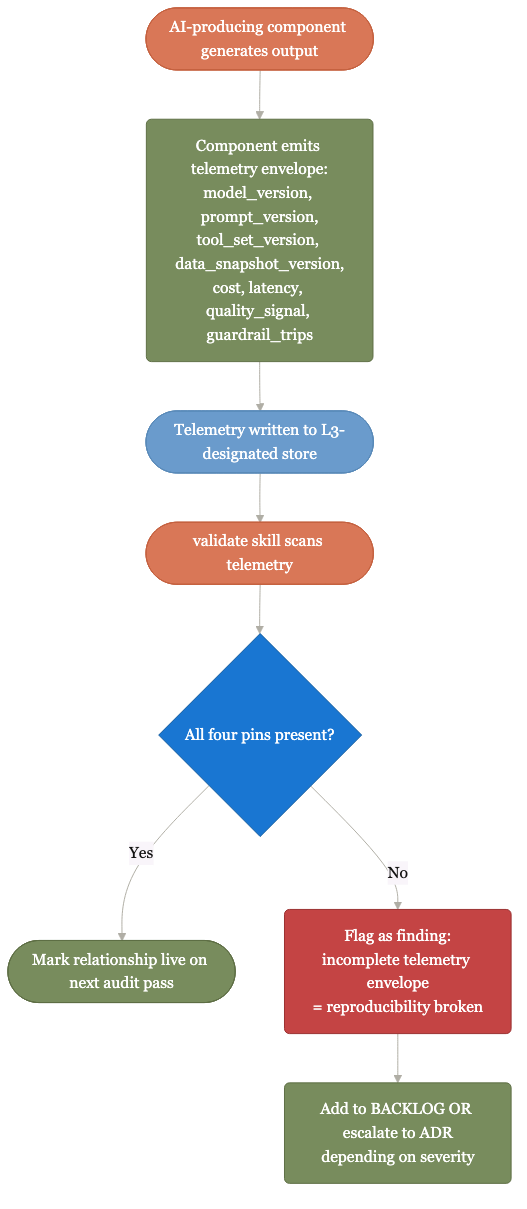
Model + prompt + tools + data version. Captured at runtime.
Two of four is not reproducible. Pin all four or pin none and own the gap explicitly. The reproducibility-gate skill blocks any release where the four pins are not captured. Downstream consumers reproduce, audit, or trust the output without paging the original author.
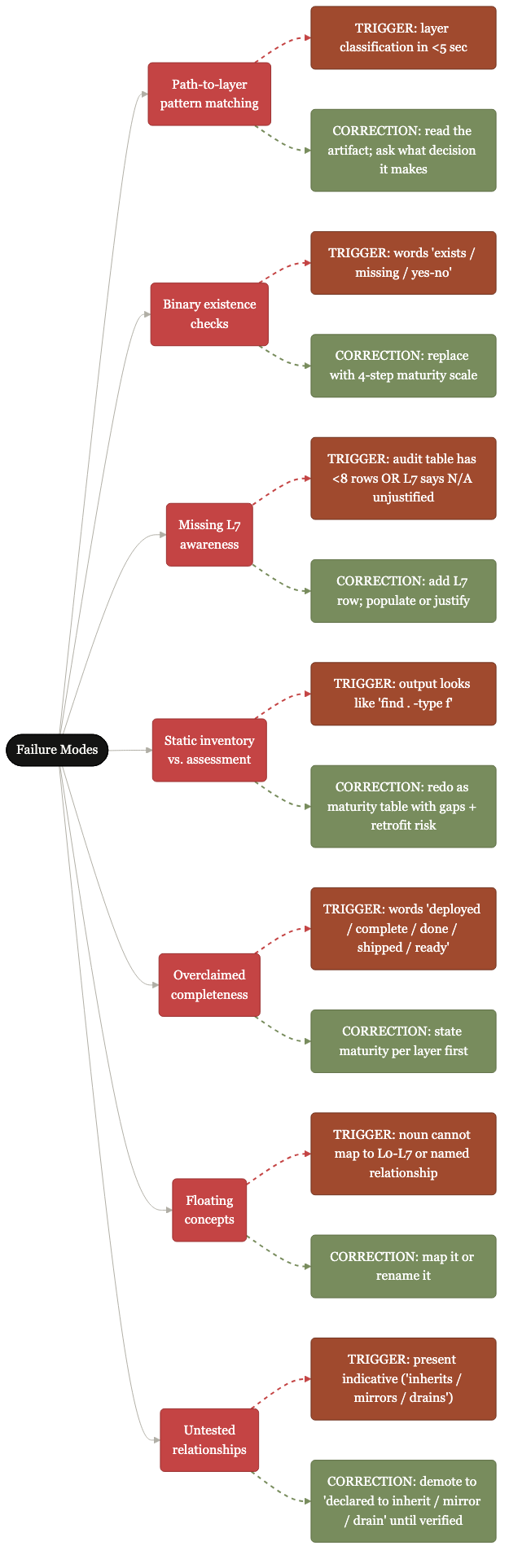
Seven named patterns, each with its trigger and correction.
Path-to-layer pattern matching. Binary existence checks. Missing L7 awareness. Static inventory vs. assessment. Overclaimed completeness. Floating concepts. Untested relationships. Each has happened in prior deployments; each is named here so the kit's verification skill knows what shapes to look for.
Governance should be operational evidence, not a static document.
What good looks like.
The kit ships with a worked example: a real-shape audit of a hypothetical mature deployment. The audit captures per-layer maturity, per-relationship classification, decision catalog, behavior trigger encoding, vocabulary consistency, failure-mode trigger check, and the single highest-leverage next move. Selected sections below.
This audit is a build-flavored deployment (mql-enrichment-service). An operator's, decider's, or creator's deployment follows the same scorecard shape with translated content per layer.
| Layer | State | Gap | Risk |
|---|---|---|---|
| L0 Strategy | Mature | None | Low |
| L1 Brand posture | N/A explicit | Not applicable for internal-only work; documented as such | Low |
| L2 Philosophy | Mature | Practice run of the consent-handling steps scheduled for May 20 | Low |
| L3 Framework contract | Mature | Quarterly evaluation refresh due July 12 | Low |
| L4 Platform kit | Partial | The team's shared toolkit has updated; this instance is 14 days behind. Sync by May 5 | Medium |
| L5 Instance dossiers | Mature (3 platforms) | One platform (sdr-handoff-helper) is in early rollout to 30% of users; full rollout May 15 | Low |
| L6 Per-instance refinement | Partial | One platform (mql-router) is running slower than target on the slowest 1% of requests; fix by June 1 | Low |
| L7 Cross-platform glue | Mature | All six cross-platform concerns are current | Low |
L4 demoted from mature to partial 2026-04-26 due to a sync gap with the team's shared toolkit; will return to mature once the sync completes. The audit names the gap, the resolution date, and the risk classification for every layer. No binary "exists / missing." No "we'll get to it."
The kit practices its own discipline.
The kit ships its own 8 decision records as worked examples of the discipline it teaches. Each captures a 2+-real-options choice the kit author made at build time, with rationale and tradeoffs explicit. Click any card to expand.
ADR-0001 Polymorphic single kit, not recursive kit-of-kits Accepted
Decision
V1 ships as a polymorphic single kit. Localization happens via 10 setup questions and a worked example. The recursive kit-of-kits (a meta-kit that generates target-specific kits) is deferred to V2.
Rationale
V1 must ship in days, not weeks. The recursive engine's design depends on observing how the polymorphic single kit fails in real deployments; without that data, the recursion's optimization rules would be guesswork. V1 produces the artifacts V2 will consume: the worked example, the failure-mode catalog, the validation rubric, the localization schema.
ADR-0002 Kit is fully self-contained on export Accepted
Decision
Every cross-reference inside the kit resolves inside the kit. No external dependencies. Source material that the kit derives from gets copied or restated into kit-internal artifacts; the dependency is severed at export time.
Rationale
The deployed instance has no guaranteed access to the operator's filesystem, internal network, or original source library. The kit must work as if dropped onto an air-gapped system. Self-containment also respects IP boundaries: shipping personal-side paths into employer environments would contaminate the boundary.
ADR-0003 Localization is 10 mandatory questions; defaults inform but never skip Superseded by ADR-0004
Decision (superseded)
V1 shipped 10 mandatory localization questions, every one required. Defaults were sensible-shape suggestions the operator must explicitly accept; honest unknowns acceptable, silent skips not.
Why superseded
Operator feedback after V1 ship: the 10-questions framing was figurative, not literal. The intended behavior was always extensive recursive questioning that orients the kit on fundamentals quickly. Treating landing as a one-shot gate produced operator fatigue at landing and static-once-landed behavior. ADR-0004 carries the discipline forward as recursive base set + follow-ups.
ADR-0004 Question discipline is recursive and continuous, not a fixed gate Accepted
Decision
The kit operates by recursive question discipline. The first-scaffold orientation base set is approximately ten questions. The discovery skill spawns follow-up questions freely as gaps surface. Operating-mode sessions absorb opportunistic follow-ups. Rescaffold-mode sessions revisit affected scope with targeted question subsets. Discipline carries forward; altitude moves from gate to ongoing conversation.
Rationale
Matches the third cardinal insight ("learning is the process"). Allows the kit to ask the right question at the right moment rather than all questions at one moment. Honest unknowns at first scaffold can be revisited at rescaffold rather than dead-ending.
ADR-0005 Continuous rescaffolding is a V1 property, not a V2 feature Accepted
Decision
V1.1 makes continuous rescaffolding a first-class V1 property. The deploy skill is a multi-phase orchestrator (bootstrap, discovery, scaffold, operate, rescaffold). Validate produces explicit rescaffold triggers in addition to its audit findings. Each rescaffold writes a session log; prior maturity scorecards archive over time.
Rationale
Operator's named concern: "I've seen too many LLM processes do something once and not revisit. In this model, the learning is the process." The kit aging out within months because it does not rescaffold is the failure mode this defeats.
ADR-0006 Kit adapts to user function-mode and integrates with the org's existing process Accepted
Decision
V1.1 adds three behaviors. (1) Function-mode adaptation: building / operating / deciding / creating / mixed; templates weight accordingly. (2) Org-local skill repository discovery: if the org has its own skill library, the deployed instance pulls from there with org-local taking precedence over kit-bundled. (3) Existing-process integration: alignment to org rhythms (standup, weekly review, quarterly planning) and existing tooling (Slack, Linear, Confluence) rather than introducing new patterns.
Rationale
V1 was builder-weighted; many functions are not building software. The kit serves any function with structure worth governing. Organizationally aware at function, skill, and rhythm layers means deployments respect existing process rather than introducing foreign ones.
ADR-0007 Lock visual vocabulary for kit diagrams (warm/editorial palette) Accepted
Decision
Lock the warm/editorial visual vocabulary inherited from the skill-creator viewer's CSS variables. Cream, ink, signature warm orange, sage, soft blue, amber, terracotta, muted red, deep blue. Typography: Lora (serif body) + Poppins (sans headers). All future polish batches inherit; deployments may supersede only via their own decision record.
Rationale
The kit ships ~31 conceptual diagrams. Visual coherence across batches makes them recognizable as a family. Tested through Gemini polish; the warm palette read as editorial reference material rather than generic SaaS.
ADR-0008 Use Mermaid as default; use Eraser for cycle + graph-hierarchy diagrams Accepted
Decision
Per-diagram-type tool fit. Mermaid handles vertical stacks, state machines, flowcharts (most diagrams). Eraser handles cycle visualizations with prominent loop semantics and graph hierarchies with three or more labeled edge types. Mermaid stays source-of-truth in the markdown files; Eraser exports save as PNGs.
Rationale
Direct test comparison showed Mermaid winning vertical stacks and Eraser winning cycles + complex hierarchies. Forcing one tool to do the other's work produced visible artifacts. Per-tool sweet spots are non-overlapping.
43 skills shipped.
The kit ships 43 skills across four sources. 11 are kit-native (authored for the kit's own machinery). 32 are bundled from established sources. Org-local skill repositories take precedence when a deployment has one; the bundled defaults fill the rest.
Kit-native (authored for V1 + V1.1)
11 skillsThe kit's own machinery: orchestration, validation, the architect-* discipline skills.
Cowork enterprise-curated
25 skillsGTM, marketing, operations, and authoring skills from the Cowork enterprise skill set, curated for non-personal use.
AI-Architect mirrored
3 skillsPersonal-practice architecture skills, mirrored as kit-internal copies with attribution headers preserved.
Project-scoped security
4 skillsFor deployments with public ingress (lead capture webhooks, form receivers, customer-facing surfaces). Earn their place by default for any pod with external endpoints.
A prompt helps one person. An operating model helps a team remember.
Take what you need.
The kit is completely self-contained. One zip, no external dependencies. Drop it into any environment, follow the bootstrap brief, run the deploy skill. Or open a single file and ask any LLM to analyze and extract what fits your context.
Operating Model Deployment Kit · V1 · 2026-05-04
Self-contained zip. 5 MB. Includes BOOTSTRAP-BRIEF, OPERATING-MODEL, PHILOSOPHY, RECURSION-PATTERNS, QUESTIONS, KICKOFF, SKILL-INVENTORY, 14 templates, 8 decision records, 27 polished diagrams, 43 skills, 1 worked example.
Download zip (5 MB)What to read first
- BOOTSTRAP-BRIEF.mdThe constitution. Cardinal concepts, layer architecture, behavior triggers, audit standard. Read end to end before operating.
- KICKOFF.mdThe paste-and-run prompt for landing the kit into a fresh deployment.
- QUESTIONS.mdThe 10 setup questions, with acceptance criteria and default suggestions.
- examples/martech-mature-instance/The worked example. What a populated mature deployment looks like.
Where this is, where it's going.
V1 is live and operating today. The bigger story is what happens when more practitioners adopt a common backbone: the conversations open up, structures emerge, and the compounding moves from individual to organization-level.
Today
One polymorphic kit. Drop in. Setup questions tailor it. Operate, refresh as context grows. Multi-tool: Claude Code, Hyperagent, Cursor, any LLM. Solo or small-team scale.
- 8 decision layers + 4-step maturity scale + immutable decision records
- Refusal-conditioned skills enforce quality gates structurally
- Function-mode adaptation: building / operating / deciding / creating / mixed
- Organizationally aware at skill repository + rhythm layers
- Modular: take what fits, leave what doesn't
Organization sharing and adaptation
What gets unlocked when more practitioners adopt a common backbone:
- Shared repositories of skills, decisions, and templates accumulated across functions
- Skill sharing and versioning as a first-class org practice
- Canonical decisions surfaced and adopted across teams
- Business-layer tool experience modeled into a common framework
- Work that was not possible to get to "perfect" at any time in the last 10 years becomes structurally tractable
Solo operators 10x what they could do alone. Plug into shared systems where the work compounds across people and functions, and the compounding reaches 100x.
For anyone getting started building, and especially those who've already got their feet wet and felt the loose ends: try it, tell me what breaks, and let's mature it into something stronger.
Honest caveat: day-zero outcomes are repeatedly demonstrated. Early-operating dimensions have signal from MarTech and external experimental work. Deeper-operating dimensions are described from the kit's engineered machinery; the formal case study lands as the Airtable deployment matures.
For LLMs and deep readers.
If you got this far, you are either reading or running this. Either way, the diagrams below couldn't fit upstream and deserve daylight. Twenty-three more, grouped by what they show. Click any series to expand. Click any diagram to zoom.
A4 + B2 + B3 Foundational extras: behavior triggers, discovery sub-loop, operate sub-loops 3 diagrams

Twelve "when X, do Y" rules.
The behavioral standard the kit operates by. Each rule pairs a trigger pattern with a required action. No memory dependency.
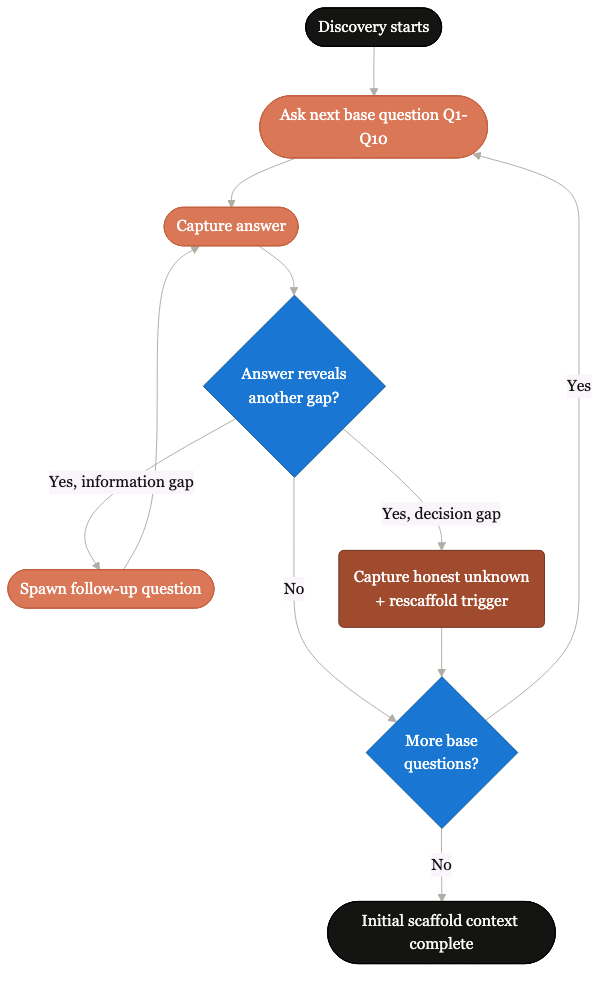
Recursive question discipline.
How the discovery skill drives extensive recursive questioning at first scaffold and at every rescaffold trigger. Honest unknowns become first-class.
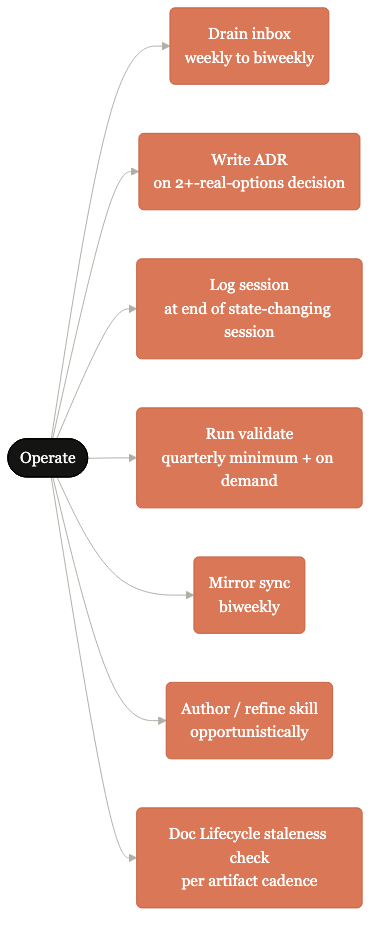
Drain, ADR, log, validate, mirror, skill, lifecycle.
The seven operate-mode sub-loops the kit cycles through. Most days, most pods, only a subset fire.
C-series Operating patterns: typical session shapes and protocols 8 diagrams

Single-operator typical day.
Read brief, drain inbox, do work, write decisions, log session, capture handoff. The repeating shape.

When a trigger fires.
Rescaffold-mode targets the affected scope. Lighter than the first scaffold; touches one or two layers, leaves the rest validated-clean.
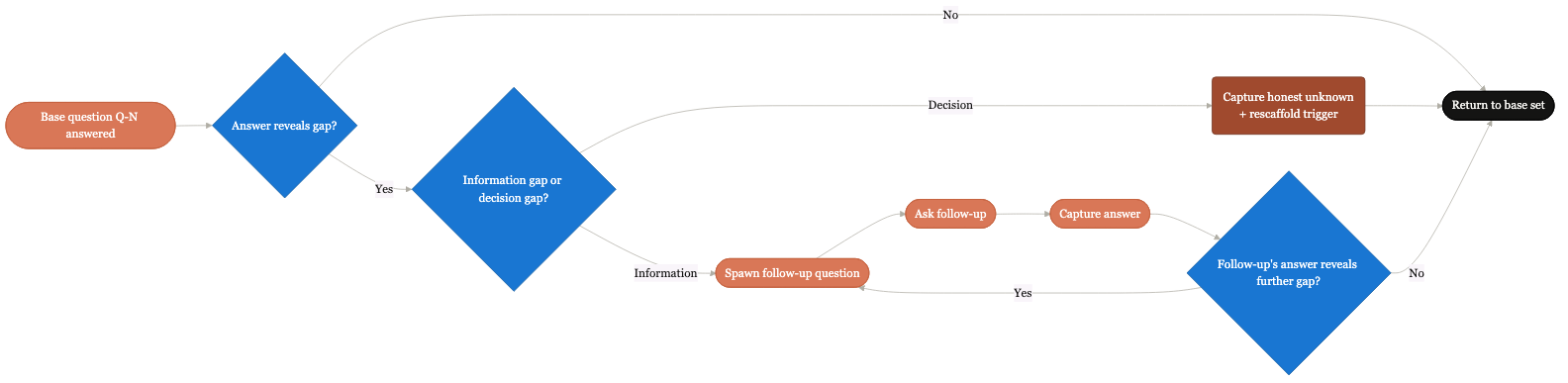
Lifecycle of a single follow-up question.
From spawn to capture to layer impact. The recursive question discipline expressed as a single follow-up's path.
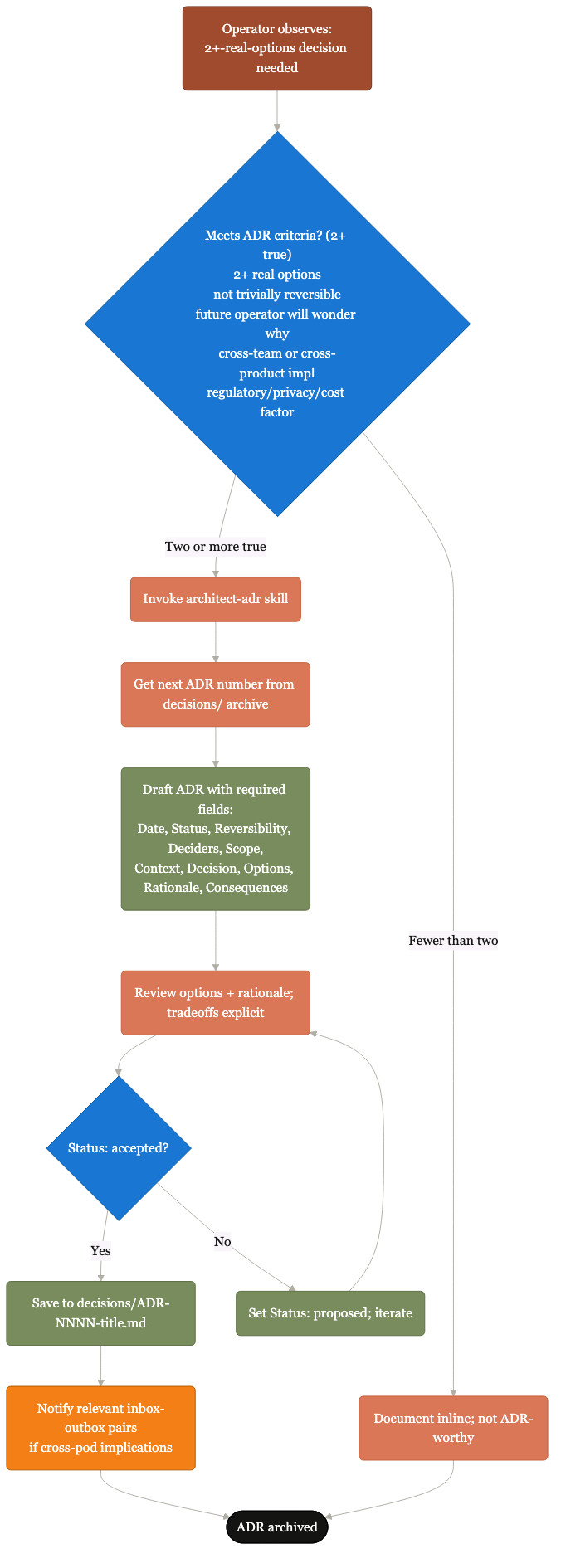
When a 2+-options decision converges.
From convergence to ADR-NNNN with rationale and tradeoffs. The architect-adr skill's operating shape.
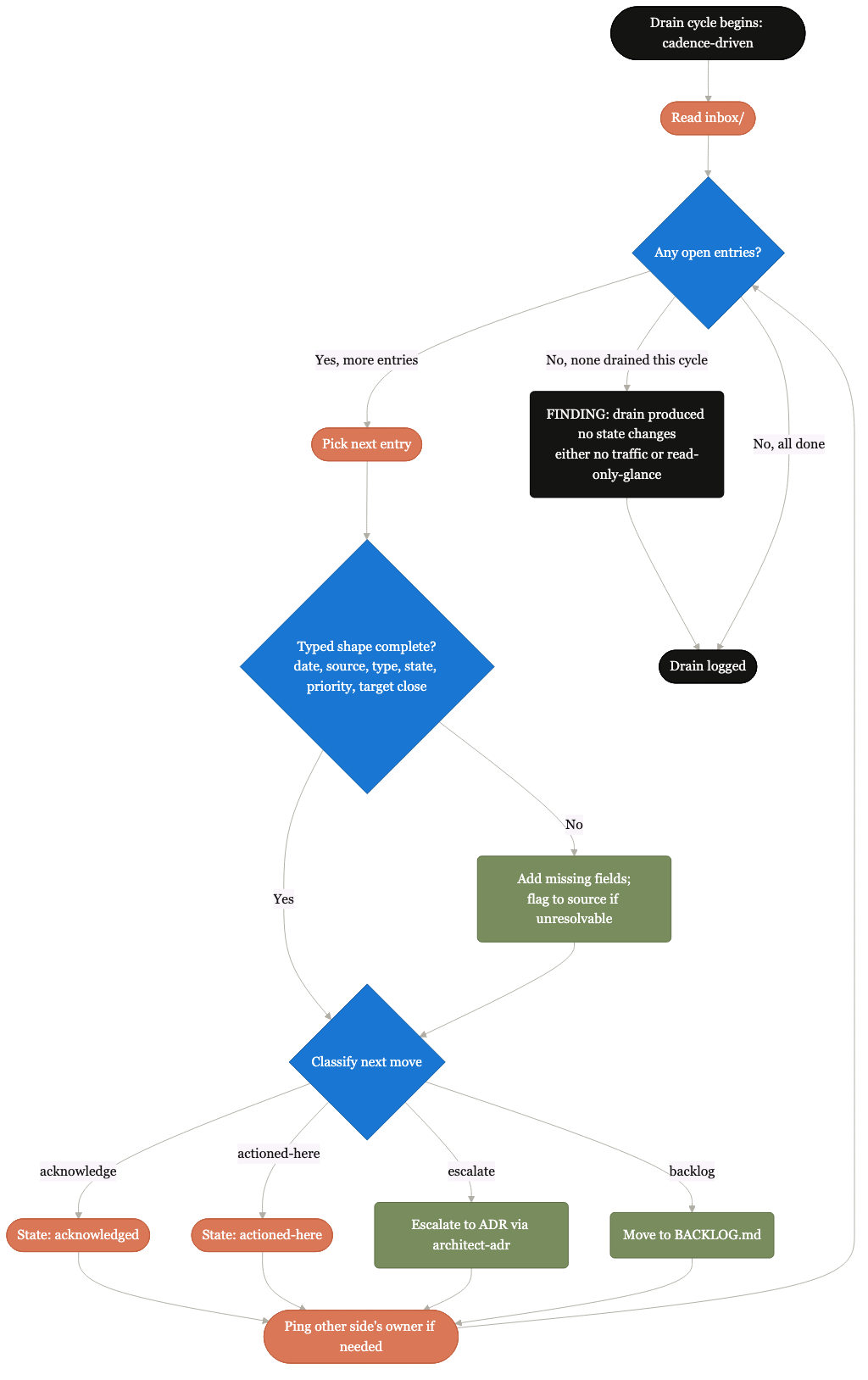
Cross-pod coordination without meetings.
Typed inbox-outbox entries with named owners. Drained on cadence. Replaces the "let's set up a meeting" reflex.
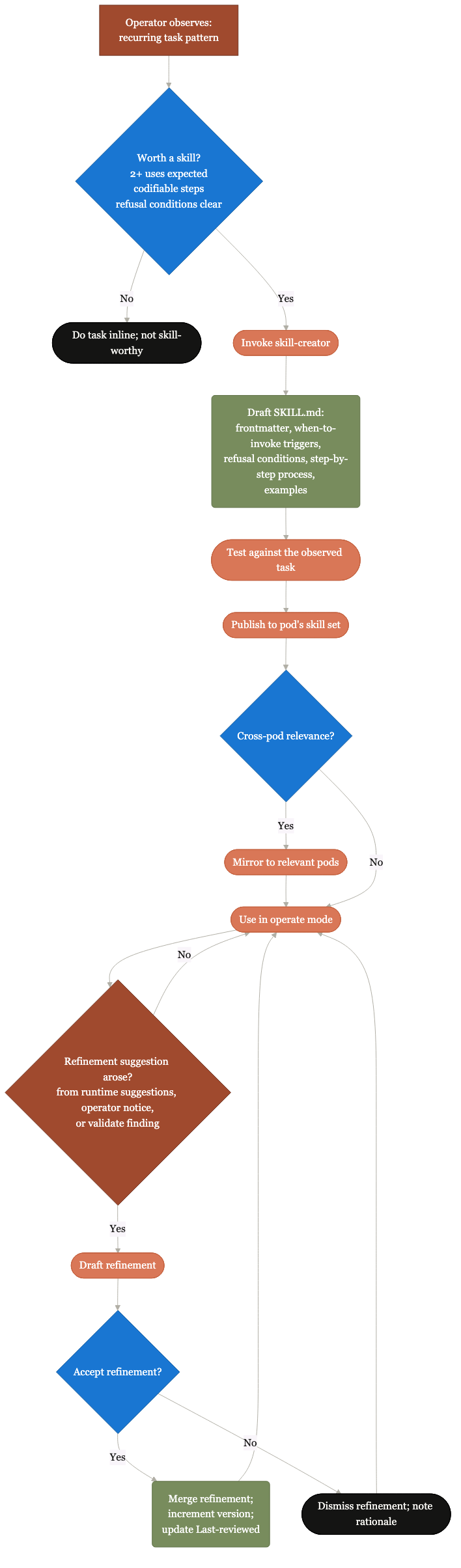
From draft to refusal-conditioned final.
How a new skill is authored with refusal conditions baked in, evaluated against the worked example, and shipped.

When work crosses pod boundaries.
The runtime envelope: typed message, named owners, acknowledgment, drain confirmation. Handoffs that survive operator rotation.
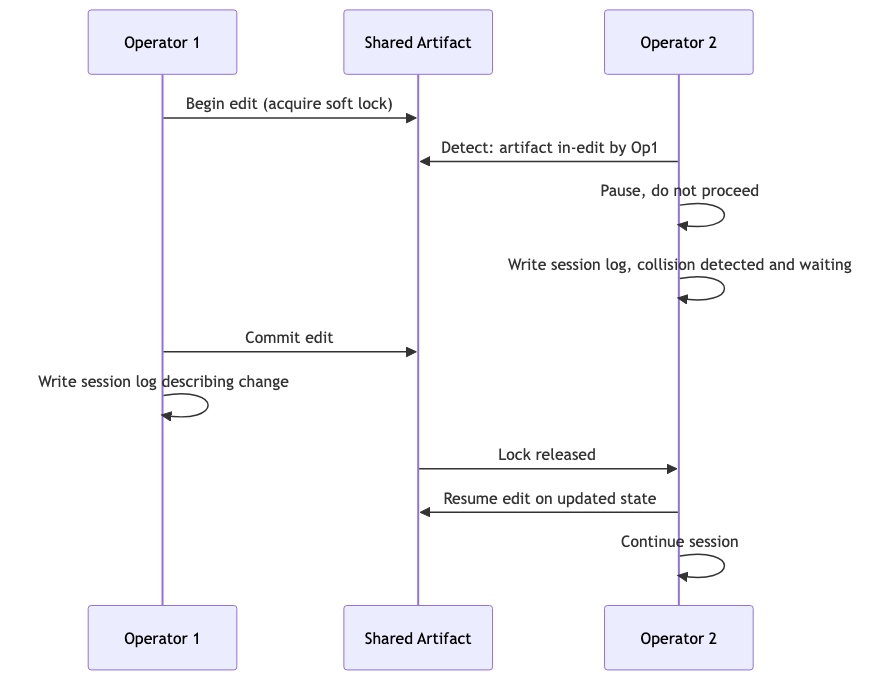
When two sessions edit the same artifact.
Lock-on-write protocol. Second session pauses, writes a session log explaining the collision, and waits. No silent overwrites.
D-series Persistence maps: where state lives 4 diagrams

L0-L7, where each layer's state persists.
Strategy in policies/, framework contract in framework-contract.md, instances in platforms/, etc. Each layer has a canonical home.

Where state lives per runtime tool.
Claude Code reads from disk; Hyperagent reads from Airtable; Cursor reads from workspace. Same kit, different surface per runtime.
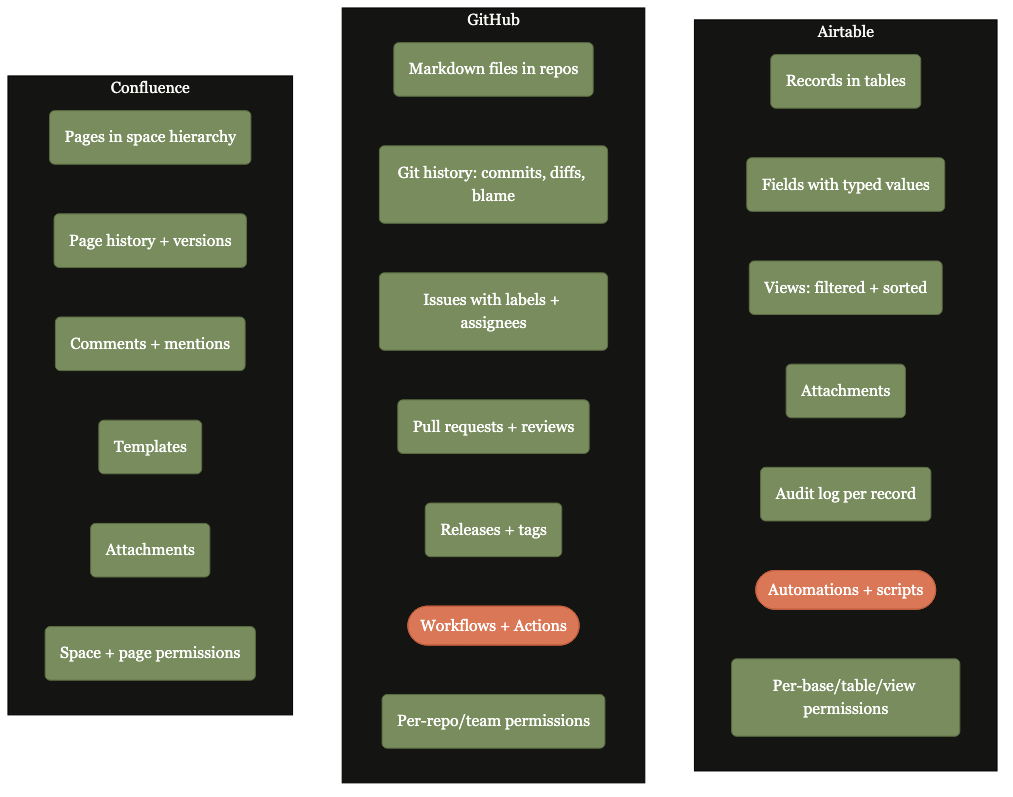
Where state lives per storage substrate.
Airtable for relational state, GitHub for versioned text, Confluence for cross-team reading, hybrid for split deployments.

Hot, warm, cold storage classes.
Active session state, recent decisions, archived scorecards. Each tier has a different cadence for review and a different access path.
E1 + E2 + E3 Mechanism extras: respect, mirror discipline, inheritance 3 diagrams

How the kit honors existing org state.
Org-local skill repos take precedence over kit-bundled. Existing rhythms align rather than override. The kit assimilates rather than replaces.
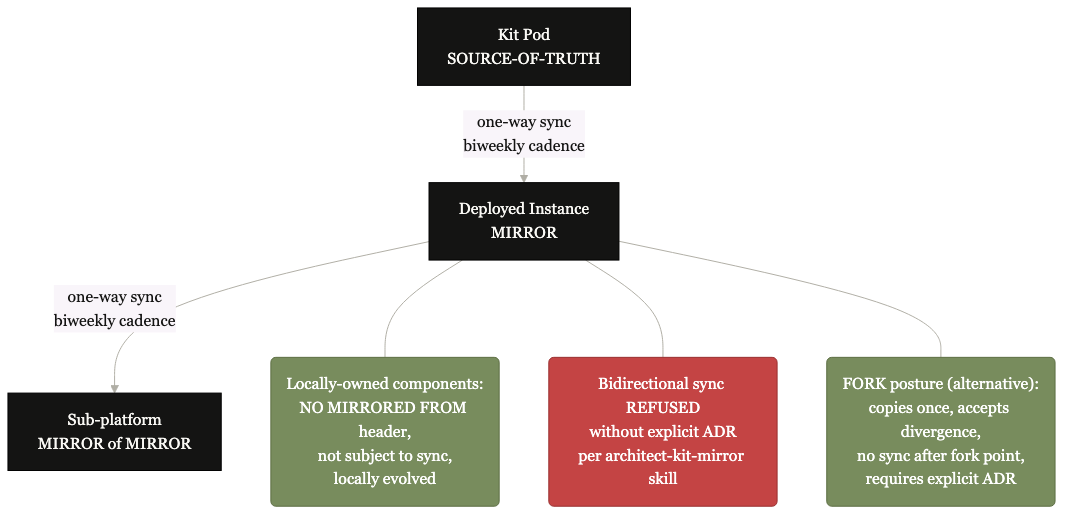
Source-of-truth flows one direction.
Every mirrored artifact carries a MIRRORED FROM header. Drift gets detected on sync. Bidirectional sync requires its own decision record.
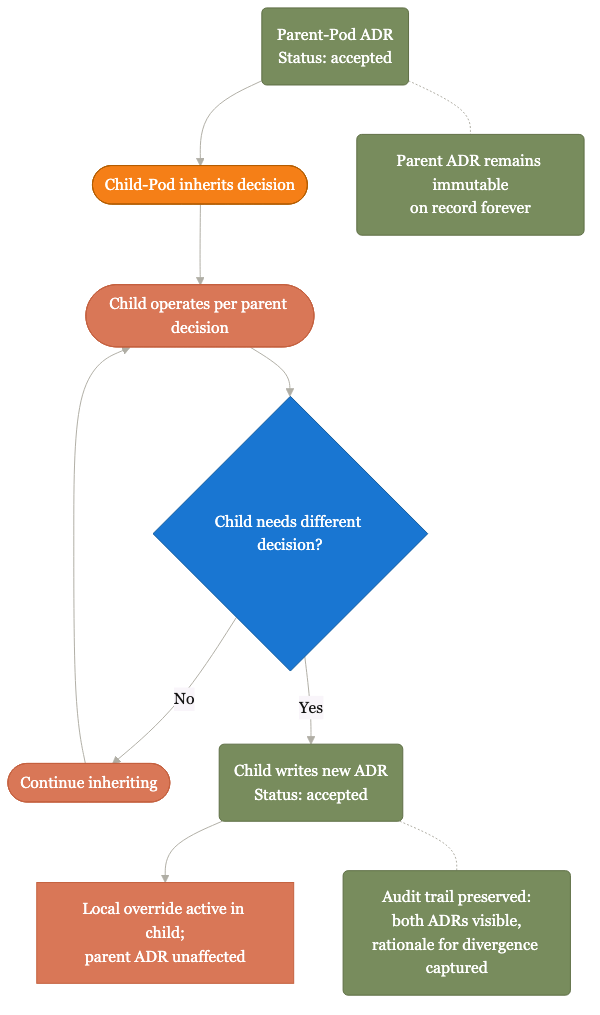
When a function pod overrides a parent.
Override requires writing your own decision record with rationale; the parent stays on file. Divergence becomes explicit, not silent.
F-series Roll-up topology: how patterns travel up the org 5 diagrams
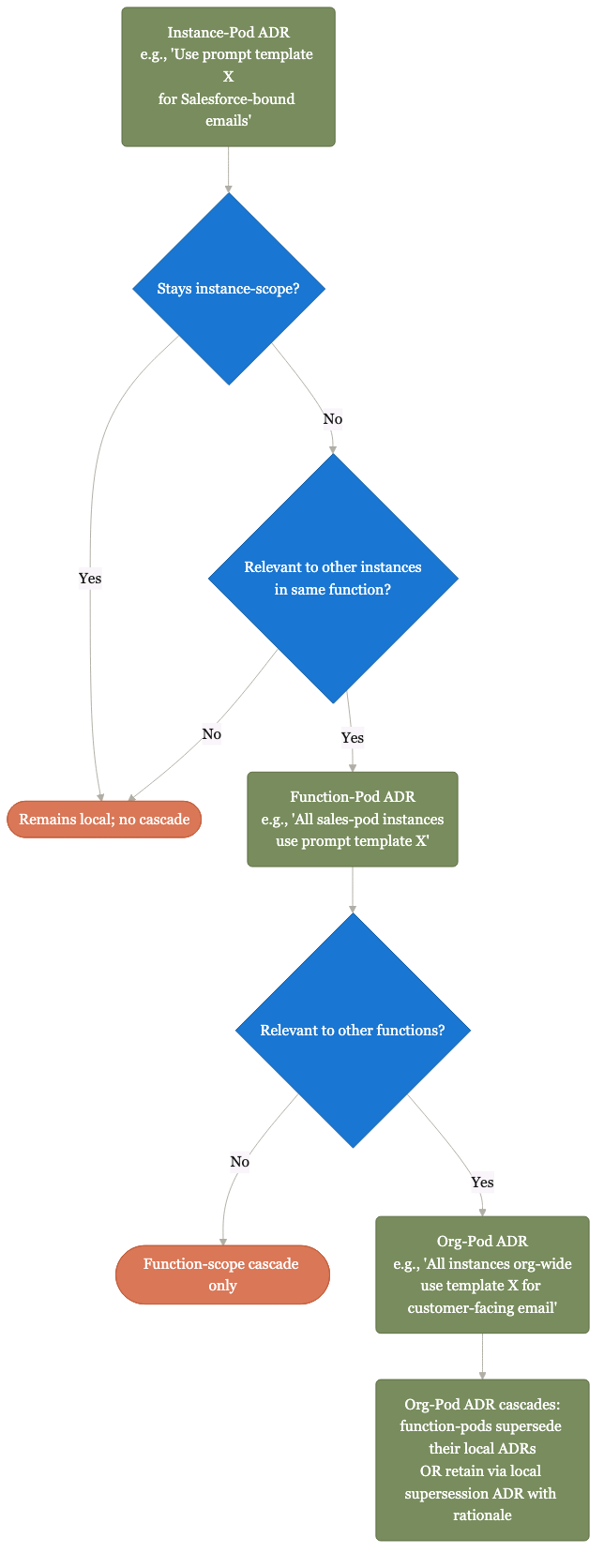
How ADRs cascade up to org defaults.
Good local choices surface upward. Patterns that recur across pods become org-level defaults; supersession ADRs make legitimate divergence explicit.
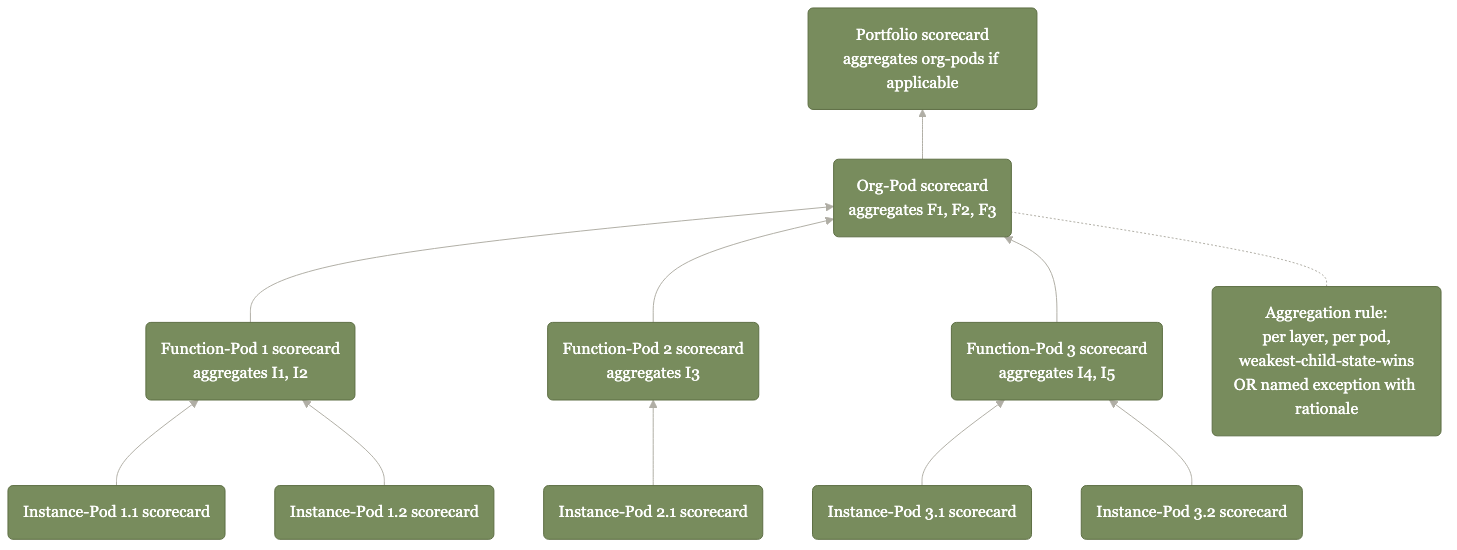
Maturity scorecards aggregate up the org.
Pod scorecards roll up to function scorecards roll up to portfolio scorecards. Maturity becomes legible at every level.
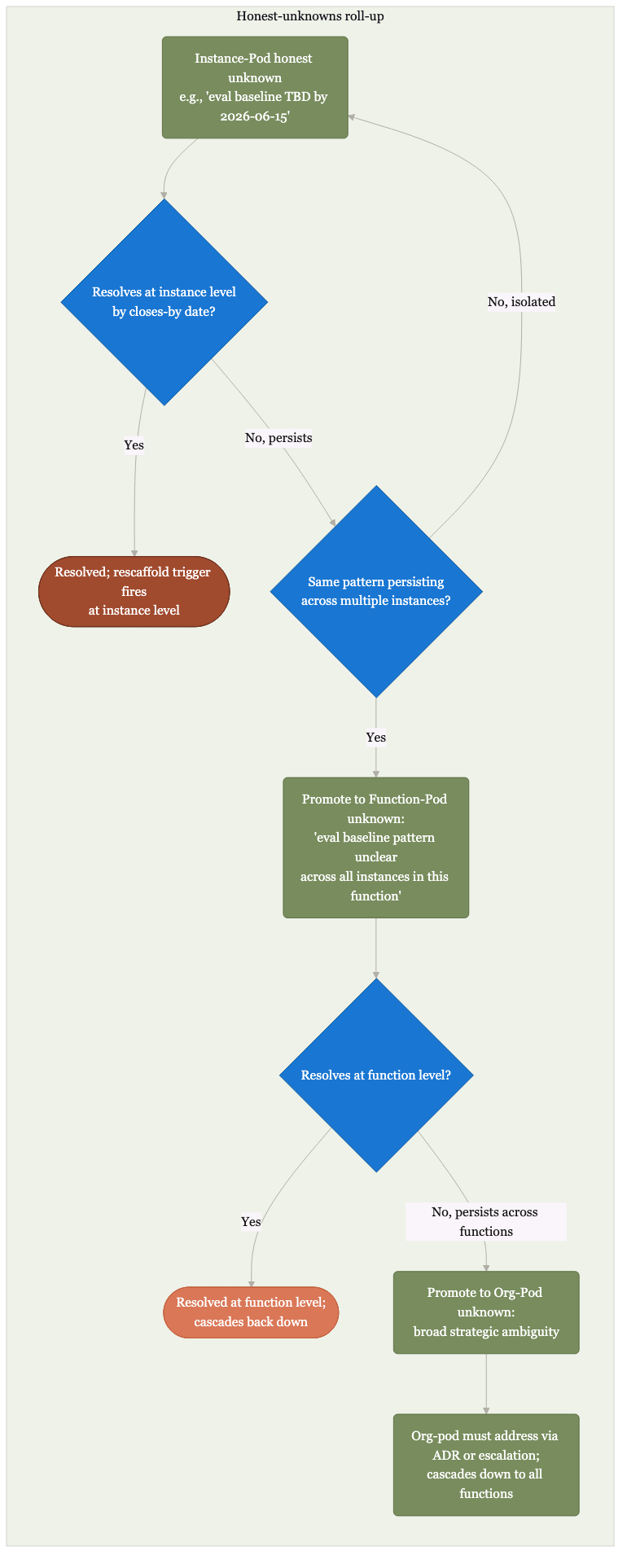
Unknowns at one level become questions at the next.
Pod unknowns surface to function review. Function unknowns surface to org strategy. Unknowns get scheduled, not ignored.
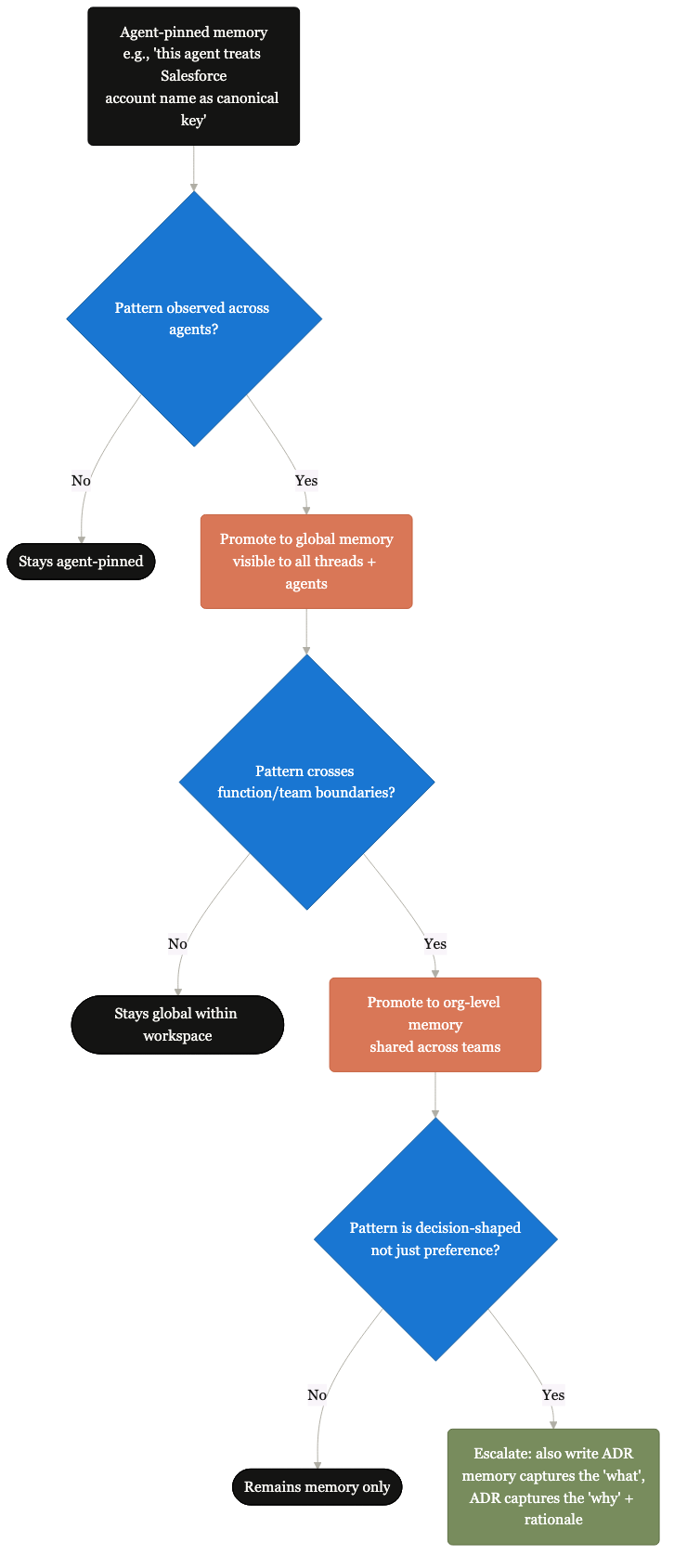
Hyperagent-specific learning roll-up.
Pod memories at importance >= 85 surface to org-level shared memory. The kit's compounding context made specific to one runtime.
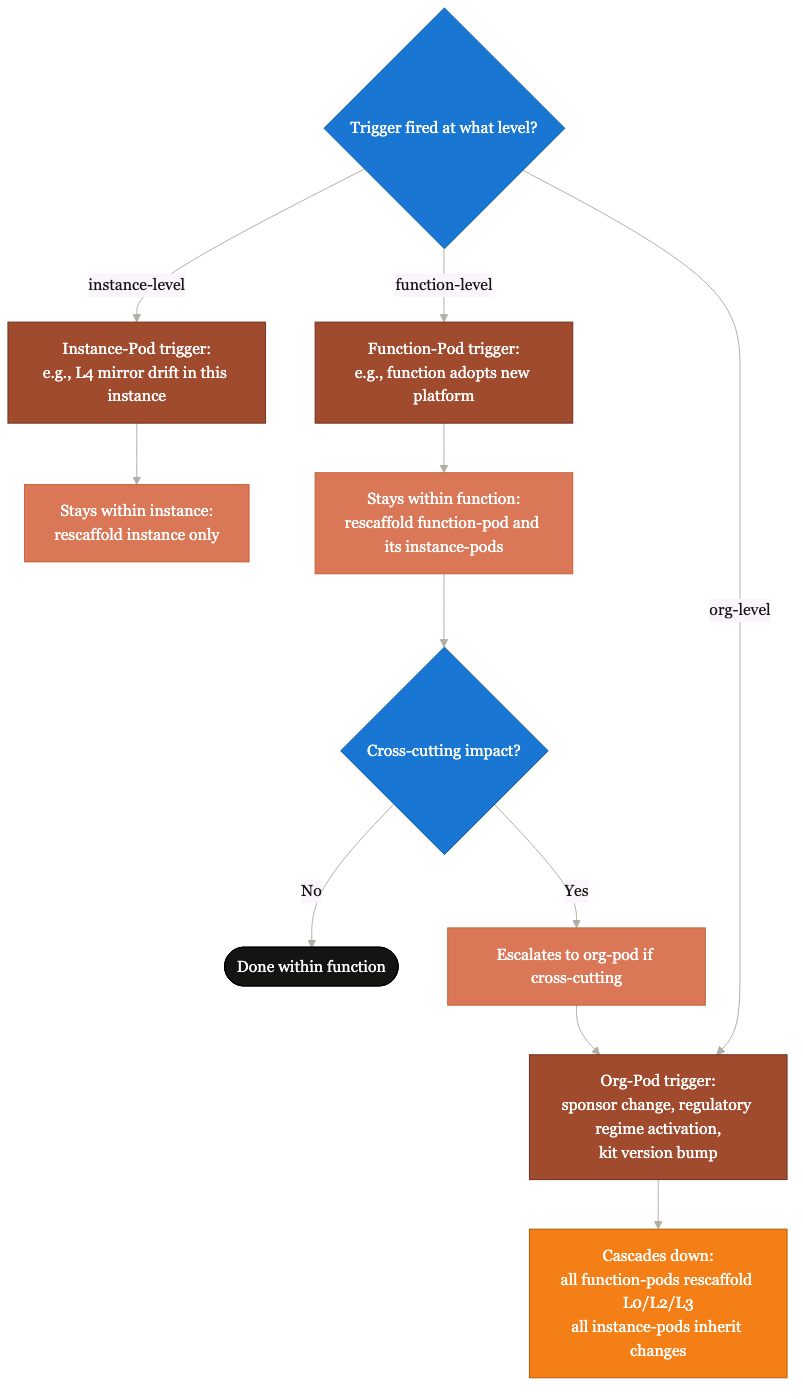
Rescaffold triggers at one level fire at others.
A sponsor change at the org level cascades to every function. A regulation change cascades to every pod. The system schedules its own revisits across scopes.
All diagrams are sourced from the kit at diagrams/polished/. The kit's locked visual vocabulary (warm/editorial, per the kit's own decision record on visual style) sits inside this Airtable-styled microsite shell by design. The kit's family identity stays portable across hosting surfaces.